“You keep using that word. I do not think it means what you think it means.” — Inigo Montoya, The Princess Bride
The word “agent” is on every pitch deck, every job listing, every LinkedIn post. The problem is that nobody agrees what it means, and they haven’t for a long time. In 1995, computer scientist Michael Wooldridge observed that “what is an agent?” was already embarrassing for the agent-based computing community. Thirty years later, the LLM era inherited the problem rather than solving it.
The major labs have all taken a shot at a definition. Anthropic draws a line between workflows and agents: if the path is predetermined, it’s a workflow, even if there’s an LLM at every step. OpenAI says agents “independently accomplish tasks on your behalf.” Simon Willison surveyed 211 crowdsourced definitions and landed on “tools in a loop.” They’re arguing about architecture, loops, and control flow, and they all have a point. But what does any of this mean for someone using these tools day to day?
I have a daily email digest that uses an LLM to pick and summarise the most interesting items from a set of sources. Is that an agent? I also have a local setup where Claude reads that same digest, researches things further, and suggests posts and notes. Is that one? And when I ask Claude to go research something and it decides on its own where to look and what to follow up on, is that something different again? The definitions don’t make it easy to draw the line, but it feels like agency has to play a significant part?
Goals produced agency, tasks didn’t
I ran 20 tests this week. Same AI model, same tools, same system instruction. The only variable was the task. Ten runs got a closed task: “research X and Y.” Ten got an open goal: “help me make sure this document covers the full landscape, start with X and Y.”
The closed-task runs scored 0 for 10. Every one researched exactly the two topics I specified, thoroughly and competently, and stopped. Not a single one looked beyond what I asked for. To make sure this wasn’t a fluke, I’d also tried changing the system instructions in earlier tests, calling the model an “advisor” instead of an “assistant,” telling it to “think laterally,” even giving it a meta-instruction: “identify the goal behind the request and serve the goal, not just the request.” None of it made a difference. The model did what it was told, nothing more.
The open-goal runs scored 10 for 10. Every one expanded beyond the two topics I’d named, identifying an average of eight additional gaps I hadn’t considered. They read the existing document, judged where the coverage was thin, and filled it without being asked to.
The difference wasn’t capability, permission, or identity. It was whether I gave it a task or a goal.
I then tested whether the language mattered. I wrote the same open goal three ways: a formally structured brief, a conversational paragraph, and a rough stream-of-consciousness prompt like you’d get from speech-to-text. All three expanded scope. The polished version wasn’t noticeably better than the messy one. What mattered was that all three described a goal, not a task. The phrasing was secondary to the goal framing. Which suggests the bottleneck isn’t building better agents, it’s learning to be a better delegator.
This is just good management
Any experienced manager knows the difference between telling someone what to do and telling them what you need. The first gets you compliance. The second gets you judgement. A junior hire needs detailed instructions because they don’t yet know what good looks like. A senior one needs the objective and the context, and then you get out of the way, because over-specifying the task actually prevents them from using the expertise you hired them for.
The Prussian field marshal Helmuth von Moltke formalised this in the 1800s as Auftragstaktik: give officers the objective and the reason behind it, let them decide how to achieve it. His reasoning was that rigid orders break down when conditions change faster than commands can travel. The same turns out to be true for LLMs. By the time the model reads the document, sees the gaps, and understands the landscape, a narrow instruction like “research X and Y” has already constrained it past the point where its judgement could add value. If you want agentic behaviour from your AI tools, the first thing to change isn’t the model or the tooling. It’s how you frame what you need.
Goal or task, latitude or not
This gives you a simple way to think about what makes something an agent, and it’s not about loops or tool calls or control flow. It’s two questions: does the system have a goal or a task? And does it have the latitude to decide how to pursue it?
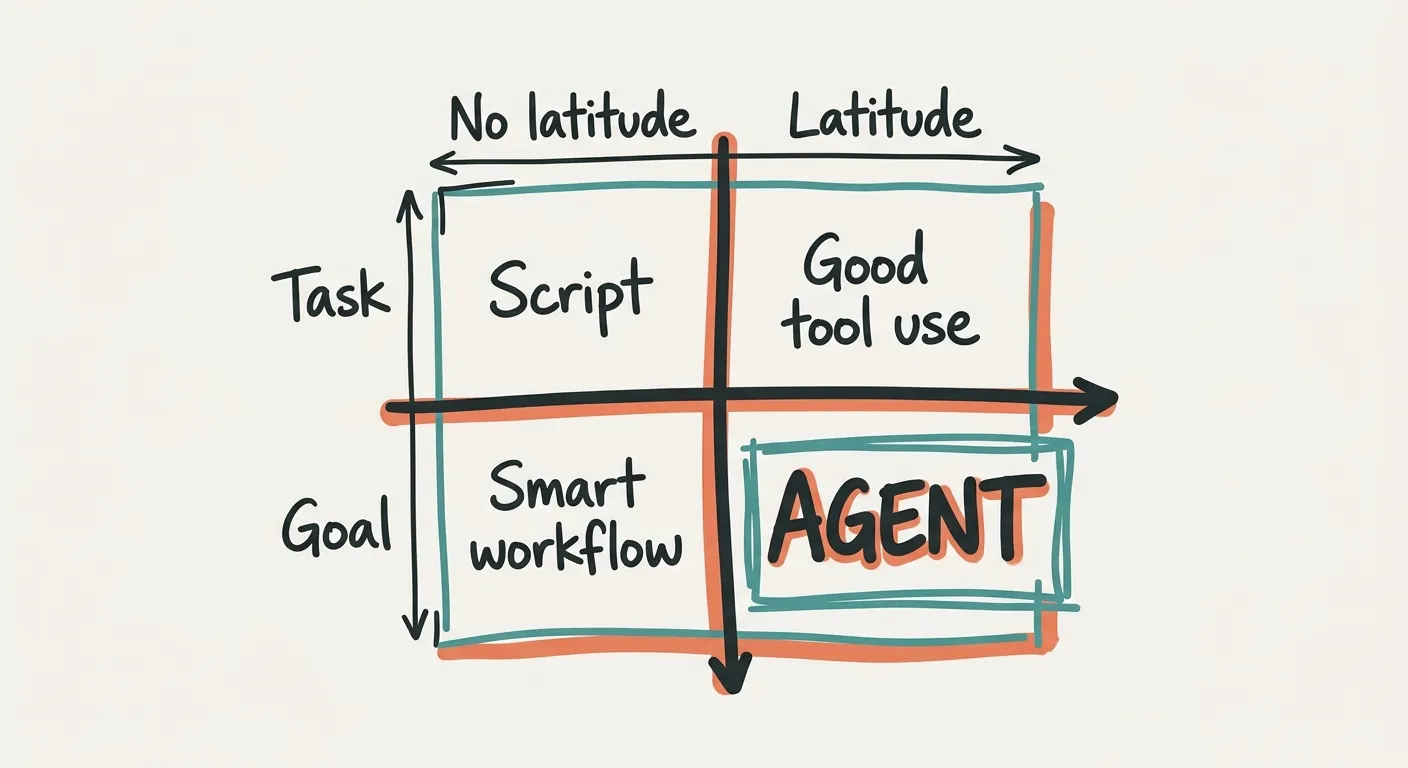
A task with no latitude is a script. Fixed steps, predictable output. A task with latitude is what most people experience when they use an AI tool well: it does what you asked, but better than you expected, because the model brings judgement to the execution. A goal with no latitude is a smart workflow, like my daily digest. It has a goal (“find what’s interesting”) but follows a fixed path to get there. It can’t decide to look elsewhere or go deeper on something unexpected.
A goal with latitude is what happened in my open-goal runs. The model understood the objective, assessed the situation, and expanded into areas I hadn’t specified. That’s an agent. It also came with a cost: I now had eight additional topics to evaluate per run instead of just the two I’d asked for. Latitude gives you judgement, but it also gives you more to check. Same trade-off as delegating to a smart colleague who keeps finding adjacent problems.
This is a behavioral definition, not an architectural one. It describes what the system does in a session, not how it’s built. Other things contribute to agency too: the tools available, persistent memory, feedback loops, token budgets. But goal framing is the fastest lever most people can actually pull, and in my testing it was the one that made the difference between a tool that executes and a system that thinks for itself.
Most things people call agents today are smart workflows. They have goals, sometimes ambitious ones, but the path to achieving them is predetermined. The model fills in slots. That’s fine, and it’s often useful, but calling it an agent borrows a word that implies something it doesn’t do.
Does the label matter?
If your AI setup solves the problem, does it matter whether it’s technically an agent by some academic definition? If you’re using “agent” as shorthand for treating an LLM as a colleague that achieves goals for you, is that really wrong?
Honestly, maybe not. The label matters less than whether the thing works.
But it matters in the other direction too. When a job listing asks for “agent experience,” does that mean building autonomous systems with tool loops and persistent memory, or does it mean you’re good at writing prompts? When a startup pitches an “AI agent” to investors, are they describing a system that makes its own decisions, or a workflow with an LLM step? The person on the other side of that conversation might be hearing something very different from what you mean. Google Trends shows searches for “agentic AI” up 843% in a single quarter in 2025, and Gartner has called most of what it describes “agent washing.”
I don’t think the word needs gatekeeping. The definitions have been argued about since 1995 and nobody’s settled it yet. But it’s worth pausing, when you use it, to think about what you actually mean. If you’re a user, agency is about goals and latitude — how you frame the work determines what you get back. If you’re an engineer, agency is about architecture — loops, tools, persistent memory, error recovery. Both are real, and neither is complete without the other. The best architecture in the world won’t behave like an agent if you give it a task instead of a goal. And the best goal framing in the world won’t help if the system can’t act on it. When we use the word, we’re often just describing a mismatch between the two.